
AIS ประเดิมแจกทองคำรอบแรกจากแคมเปญ “AIS Check ID” ลุ้นรางวัลมูลค่ารวม 1.6 ล้านบาท
AIS มอบทองคำให้ผู้โชคดี 60 รายจากแคมเปญ "AIS Check ID" ชวนลูกค้ายืนยันตัวตนและอัปเดตข้อมูล ลุ้นทองคำต่อเนื่องถึง 30 เม.ย. 68

AWS เปิดตัว อินสแตนซ์ Amazon EC2 ใหม่สามรายการ Hpc7g, C7gn และ Inf2 ที่ขับเคลื่อนโดยชิปที่ออกแบบโดย AWS เพื่อมอบประสิทธิภาพการประมวลผลที่ดียิ่งขึ้นแก่ลูกค้าด้วยต้นทุนที่ต่ำลง

อะเมซอน เว็บ เซอร์วิสเซส (Amazon Web Services: AWS) บริษัทในเครือ Amazon.com ได้ประกาศเปิดตัว อินสแตนซ์ Amazon Elastic Compute Cloud (Amazon EC2) ใหม่สามรายการที่ขับเคลื่อนโดยชิปที่ออกแบบโดย AWS ซึ่งให้ประสิทธิภาพการประมวลผลที่ดียิ่งขึ้นแก่ลูกค้าด้วยต้นทุนที่ต่ำลงสําหรับปริมาณงานที่หลากหลาย Hpc7g Instances ขับเคลื่อนโดยชิป AWS Graviton3E ใหม่ ให้ประสิทธิภาพการประมวลผลจุดลอยตัวต่อวินาที (floating-point performance) ที่ดีขึ้นถึง 2 เท่า เมื่อเทียบกับอินสแตนซ์ C6gn รุ่นปัจจุบัน และประสิทธิภาพที่สูงขึ้นถึง 20% เมื่อเทียบกับอินสแตนซ์ Hpc6a รุ่นปัจจุบัน ซึ่งมอบประสิทธิภาพด้านราคาที่ดีที่สุดสําหรับการประมวลผลประสิทธิภาพสูง (High performance computing: HPC) บน AWS C7gn Instances ที่มี AWS Nitro Cards ใหม่ ให้อัตราการส่งถ่ายข้อมูลในเครือข่ายเพิ่มขึ้นถึง 2 เท่า และประสิทธิภาพแพ็กเก็ตต่อวินาทีเพิ่มขึ้น 2 เท่าต่อ CPU เมื่อเทียบกับอินสแตนซ์ที่ปรับให้เหมาะสมกับเครือข่ายรุ่นปัจจุบัน ซึ่งมอบอัตราการส่งถ่ายข้อมูลในเครือข่ายและประสิทธิภาพอัตราแพ็คเก็ตสูงสุด รวมถึงประสิทธิภาพด้านราคาที่ดีที่สุดสําหรับปริมาณงานที่ใช้เครือข่ายมาก Inf2 Instances ซึ่งขับเคลื่อนโดยชิป AWS Inferentia2 ใหม่สร้างขึ้นเพื่อเรียกใช้โมเดลการเรียนรู้เชิงลึก (Deep learning) ที่ใหญ่ที่สุดถึง 175 พันล้านพารามิเตอร์ และให้ปริมาณการประมวลผลสูงถึง 4 เท่า และเวลาแฝงลดลงสูงสุด 10 เท่าเมื่อเทียบกับอินสแตนซ์ Inf1 รุ่นปัจจุบัน ซึ่งให้เวลาแฝงต่ำสุดด้วยต้นทุนที่ต่ำที่สุดสําหรับการอนุมานของแมชชีนเลิร์นนิง (Machine learning: ML) บน Amazon EC2
AWS มีประสบการณ์กว่าทศวรรษในการออกแบบชิปที่พัฒนาขึ้นเพื่อประสิทธิภาพและความสามารถในการปรับขยายในระบบคลาวด์ด้วยต้นทุนที่ต่ำลง ที่ผ่านมา AWS ได้เปิดตัวการออกแบบชิปแบบพิเศษ ซึ่งทําให้ลูกค้าสามารถเรียกใช้ปริมาณงานที่มีความต้องการสูงขึ้นด้วยคุณสมบัติที่แตกต่างกันซึ่งต้องการการประมวลผลที่รวดเร็วขึ้น, ความจุหน่วยความจําที่สูงขึ้น, พื้นที่จัดเก็บที่รับส่งข้อมูลได้เร็วขึ้น และอัตราการส่งถ่ายข้อมูลในเครือข่ายที่เพิ่มขึ้น นับตั้งแต่เปิดตัว AWS Nitro System ในปี 2013 AWS ได้พัฒนานวัตกรรมซิลิคอนที่ออกแบบโดย AWS หลายรุ่น ซึ่งรวมถึง Nitro System ห้ารุ่น, ชิป Graviton สามรุ่นที่ปรับให้เหมาะสมกับประสิทธิภาพและต้นทุนสําหรับปริมาณงานที่หลากหลาย, ชิป Inferentia สองรุ่นสําหรับการอนุมานของ ML และชิป Trainium สําหรับการเทรน ML นอกจากนี้ AWS ใช้ระบบอัตโนมัติในการออกแบบทางอิเล็กทรอนิกส์บนคลาวด์ ซึ่งเป็นส่วนหนึ่งของวงจรการพัฒนาที่คล่องตัวสําหรับการออกแบบและการตรวจสอบซิลิคอนที่ออกแบบโดย AWS ช่วยให้ทีมสามารถสร้างสรรค์นวัตกรรมได้เร็วขึ้นและทําให้ชิปพร้อมใช้งานสําหรับลูกค้าได้รวดเร็วยิ่งขึ้น ด้วยชิปแต่ละตัวที่ต่อเนื่องกัน AWS สามารถส่งมอบชิปใหม่ที่ใช้กระบวนการซิลิคอนที่ทันสมัยและประหยัดพลังงานมากขึ้นในระยะเวลาที่คาดการณ์ได้และรวดเร็ว AWS นำเสนอการปรับปรุงประสิทธิภาพการทำงานของขั้นตอน ต้นทุน และประสิทธิภาพให้กับอินสแตนซ์ Amazon EC2 ที่โฮสต์ชิปเหล่านั้น ทําให้ลูกค้ามีทางเลือกมากขึ้นในการผสมผสานชิปและอินสแตนซ์ที่ปรับให้เหมาะสมกับความต้องการปริมาณงานต่าง ๆ

“ซิลิคอนแต่ละรุ่นที่ออกแบบโดย AWS ตั้งแต่ชิป Graviton ไปจนถึง Trainium, Inferentia และ Nitro Cards มอบประสิทธิภาพที่เพิ่มขึ้น ต้นทุนที่ต่ำลง และประสิทธิภาพการใช้พลังงานสําหรับปริมาณงานของลูกค้าที่หลากหลาย” เดวิด บราวน์ รองประธานของ Amazon EC2 ของ AWS กล่าวว่า “การส่งมอบที่ต่อเนื่อง รวมกับความสามารถของลูกค้าในการเพิ่มประสิทธิภาพด้านราคาที่ดีขึ้นโดยใช้ AWS Silicon ช่วยขับเคลื่อนนวัตกรรมที่ไม่หยุดนิ่งของเรา อินสแตนซ์ Amazon EC2 ที่เราแนะนําในวันนี้มีการปรับปรุงที่สําคัญสําหรับปริมาณงาน HPC ปริมาณงานที่ใช้เครือข่ายมาก และการอนุมาน ML ทำให้ลูกค้าสามารถเลือกอินสแตนซ์ได้มากขึ้นเพื่อตอบสนองความต้องการเฉพาะของพวกเขา”
องค์กรในหลายอุตสาหกรรมใช้ HPC ในการแก้ปัญหาทางวิชาการ วิทยาศาสตร์ และธุรกิจที่ซับซ้อน ปัจจุบัน ลูกค้าอย่าง AstraZeneca, Formula 1 และ Maxar Technologies ใช้ปริมาณงาน HPC แบบเดิม เช่น การประมวลผลจีโนมิกส์ พลศาสตร์ของไหลเชิงคํานวณ (Computational fluid dynamics: CFD) และการจําลองการพยากรณ์อากาศบน AWS เพื่อใช้ประโยชน์จากความปลอดภัย ความสามารถในการปรับขนาด และความยืดหยุ่นที่เหนือกว่าของ AWS วิศวกร นักวิจัย และนักวิทยาศาสตร์เรียกใช้ปริมาณงาน HPC บนอินสแตนซ์ Amazon EC2 ที่ปรับให้เหมาะสมกับ HPC (เช่น Hpc6a, Hpc6id, C5n, R5n, M5n และ C6gn) ซึ่งช่วยในการประมวลผลที่ไม่จํากัดและอัตราการส่งถ่ายข้อมูลในเครือข่ายระดับสูงระหว่างเซิร์ฟเวอร์ที่ประมวลผลและแลกเปลี่ยนข้อมูลระหว่างคอร์นับพัน แม้ว่าประสิทธิภาพของอินสแตนซ์เหล่านี้จะเพียงพอสําหรับการใช้งาน HPC ส่วนใหญ่ในปัจจุบัน แต่แอปพลิเคชันที่เกิดขึ้นใหม่ เช่น ปัญญาประดิษฐ์ (AI) และยานพาหนะอัตโนมัติต้องการอินสแตนซ์ที่ปรับให้เหมาะกับ HPC ซึ่งสามารถปรับขนาดเพิ่มเติมเพื่อแก้ปัญหาที่ยากขึ้นเรื่อย ๆ และลดต้นทุนของปริมาณงาน HPC ซึ่งสามารถปรับขนาดได้เป็นหลายหมื่นคอร์ขึ้นไป
Hpc7g Instances ที่ขับเคลื่อนโดยโปรเซสเซอร์ AWS Graviton3E ใหม่มอบประสิทธิภาพด้านราคาที่ดีที่สุดสําหรับปริมาณงาน HPC ของลูกค้า (เช่น CFD, การจําลองสภาพอากาศ, จีโนมิกส์ และพลศาสตร์โมเลกุล) บน Amazon EC2 อินสแตนซ์ Hpc7g ให้ประสิทธิภาพจุดลอยตัวที่ดีขึ้นถึง 2 เท่าเมื่อเทียบกับอินสแตนซ์ C6gn รุ่นปัจจุบันที่ขับเคลื่อนโดยโปรเซสเซอร์ Graviton2 และประสิทธิภาพที่สูงขึ้นถึง 20% เมื่อเทียบกับอินสแตนซ์ Hpc6a รุ่นปัจจุบัน ทําให้ลูกค้าสามารถทําการคํานวณที่ซับซ้อนในคลัสเตอร์ HPC ได้สูงสุดหลายหมื่นคอร์ อินสแตนซ์ Hpc7g ยังมีแบนด์วิดท์หน่วยความจําสูงและอัตราการส่งถ่ายข้อมูลในเครือข่ายต่อ CPU สูงสุดในอินสแตนซ์ AWS ทั้งหมด เพื่อให้ได้ผลลัพธ์ที่เร็วขึ้นสําหรับแอปพลิเคชัน HPC ลูกค้าสามารถใช้อินสแตนซ์ Hpc7g กับ AWS ParallelCluster ซึ่งเป็นเครื่องมือการจัดการคลัสเตอร์แบบโอเพนซอร์ส เพื่อจัดเตรียมอินสแตนซ์ Hpc7g ควบคู่ไปกับอินสแตนซ์ประเภทอื่น ๆ ทําให้ลูกค้ามีความยืดหยุ่นในการเรียกใช้ปริมาณงานประเภทต่าง ๆ ภายในคลัสเตอร์ HPC เดียวกัน
ลูกค้าใช้อินสแตนซ์ที่ปรับให้เหมาะกับเครือข่ายของ Amazon EC2 เพื่อเรียกใช้ปริมาณงานที่ต้องใช้เครือข่ายมาก เช่น การใช้งานเครือข่ายเสมือน (เช่น ไฟร์วอลล์ เราเตอร์เสมือน และโหลดบาลานเซอร์) และการเข้ารหัสข้อมูล ลูกค้าจําเป็นต้องปรับขนาดประสิทธิภาพของปริมาณงานเหล่านี้เพื่อจัดการกับปริมาณการใช้งานเครือข่ายที่เพิ่มขึ้น เพื่อรองรับการใช้งานที่เพิ่มขึ้นอย่างรวดเร็ว หรือเพื่อลดเวลาในการประมวลผลและมอบประสบการณ์ที่ดีขึ้นให้แก่ผู้ใช้งาน ปัจจุบัน ลูกค้าใช้อินสแตนซ์ขนาดใหญ่ขึ้นเพื่อรองรับปริมาณการประมวลผลที่มากขึ้น โดยปรับใช้ทรัพยากรการประมวลผลมากกว่าที่จําเป็น ซึ่งเป็นการเพิ่มค่าใช้จ่าย ลูกค้าเหล่านี้ต้องการประสิทธิภาพแพ็กเก็ตต่อวินาทีที่เพิ่มขึ้น อัตราการส่งถ่ายข้อมูลในเครือข่ายที่สูงขึ้น และประสิทธิภาพการเข้ารหัสที่เร็วขึ้นเพื่อลดเวลาในการประมวลผลข้อมูล
C7gn Instances ที่มี AWS Nitro Cards ใหม่ที่ขับเคลื่อนโดยชิป Nitro รุ่นใหม่รุ่นที่ 5 พร้อมการเร่งความเร็วเครือข่าย ให้อัตราการส่งถ่ายข้อมูลในเครือข่ายและประสิทธิภาพการประมวลผลแพ็คเก็ตที่ปรับให้เหมาะสมกับ Amazon EC2 ที่เพิ่มประสิทธิภาพเครือข่าย Nitro Cards จะลดภาระและเร่งความเร็วอินพุต/เอาต์พุตสําหรับฟังก์ชันต่าง ๆ จาก CPU ของโฮสต์ไปยังฮาร์ดแวร์เฉพาะเพื่อใช้ประสิทธิภาพทั้งหมดของอินสแตนซ์ Amazon EC2 กับปริมาณงานของลูกค้าเพื่อประสิทธิภาพที่สม่ำเสมอมากขึ้นด้วยการใช้งาน CPU ที่น้อยลง AWS Nitro Cards ใหม่ช่วยให้อินสแตนซ์ C7gn ทำให้อัตราการส่งถ่ายข้อมูลในเครือข่ายเพิ่มขึ้นถึง 2 เท่า และประสิทธิภาพแพ็กเก็ตต่อวินาทีเพิ่มขึ้น 2 เท่าต่อ CPU และลดเวลาแฝงของเครือข่าย Elastic Fabric Adapter (EFA) เมื่อเทียบกับอินสแตนซ์ Amazon EC2 รุ่นปัจจุบัน อินสแตนซ์ C7gn ยังมอบประสิทธิภาพการประมวลผลที่ดีขึ้นถึง 25% และประสิทธิภาพการทำงานที่เร็วขึ้นสูงสุด 2 เท่าสําหรับการเข้ารหัสเมื่อเทียบกับอินสแตนซ์ C6gn อินสแตนซ์ C7gn ช่วยให้ลูกค้าปรับขนาดได้ทั้งด้านประสิทธิภาพและปริมาณการประมวลผล และลดเวลาแฝงของเครือข่ายเพื่อเพิ่มประสิทธิภาพต้นทุนของปริมาณงานที่มีความต้องการใช้เครือข่ายสูงบน Amazon EC2 ให้เหมาะสม อินสแตนซ์ C7gn พร้อมให้ใช้งานแล้ววันนี้ในแบบพรีวิว
นักวิทยาศาสตร์ข้อมูลและวิศวกร ML กําลังสร้าง deep learning ที่ใหญ่ขึ้นและซับซ้อนมากขึ้น เพื่อตอบสนองต่อความต้องการแอปพลิเคชันที่ดีขึ้นและประสบการณ์ส่วนบุคคลที่ปรับแต่งให้เหมาะสมยิ่งขึ้น ตัวอย่างเช่น โมเดลภาษาขนาดใหญ่ (LLMs) ที่มีพารามิเตอร์มากกว่า 100 พันล้านตัวกำลังแพร่หลายมากขึ้นเรื่อย ๆ โดยฝึกฝนกับข้อมูลจำนวนมหาศาล ซึ่งขับเคลื่อนความต้องการด้านการประมวลผลที่เติบโตอย่างที่ไม่เคยมีมาก่อน แม้ว่าการฝึกอบรมจะได้รับความสนใจอย่างมาก แต่การอนุมานจะคํานึงถึงความซับซ้อนและค่าใช้จ่ายส่วนใหญ่ (เช่น สําหรับทุก ๆ 1 ดอลลาร์ที่ใช้ไปกับการฝึกอบรม จะใช้เงินมากถึง 9 ดอลลาร์ในการอนุมาน) ของการใช้แมชชีนเลิร์นนิงในการผลิต ซึ่งสามารถจํากัดการใช้งานและหยุดการสร้างนวัตกรรมของลูกค้า ลูกค้าต้องการใช้โมเดลการเรียนรู้เชิงลึกที่ล้ำสมัยในแอปพลิเคชันของตนในวงกว้าง แต่ถูกจํากัดด้วยต้นทุนการประมวลผลที่สูง ในปี 2019 เมื่อ AWS เปิดตัวอินสแตนซ์ Inf1 โมเดลการเรียนรู้เชิงลึกที่มีพารามิเตอร์นับล้าน ตั้งแต่นั้นมา ขนาดและความซับซ้อนของโมเดลการเรียนรู้เชิงลึกได้เติบโตขึ้นอย่างทวีคูณ โดยโมเดลการเรียนรู้เชิงลึกบางโมเดลที่มีพารามิเตอร์มากกว่าหลายแสนล้านพารามิเตอร์ ซึ่งเพิ่มขึ้น 500 เท่า ลูกค้าที่ทํางานบนแอปพลิเคชันรุ่นต่อไปโดยใช้การเรียนรู้เชิงลึกที่พัฒนาล่าสุด ต้องการฮาร์ดแวร์ที่คุ้มค่าและประหยัดพลังงานซึ่งมีเวลาแฝงต่ำและปริมาณงานสูงด้วยซอฟต์แวร์ที่ยืดหยุ่น ซึ่งช่วยให้ทีมวิศวกรสามารถปรับใช้นวัตกรรมล่าสุดของตนในวงกว้างได้อย่างรวดเร็ว
Inf2 Instances ซึ่งขับเคลื่อนโดยชิป Inferentia2 ใหม่ รองรับ deep learning ขนาดใหญ่ (เช่น LLM การสร้างอิมเมจ และการตรวจจับเสียงพูดอัตโนมัติ) ที่มีพารามิเตอร์สูงสุด 175 พันล้านพารามิเตอร์ ในขณะที่ให้ต้นทุนต่อการอนุมานที่ต่ำที่สุดบน Amazon EC2 อินสแตนซ์ Inf2 เป็นอินสแตนซ์แรกที่ปรับให้เหมาะสมกับการอนุมานที่รองรับการอนุมานแบบกระจาย ซึ่งเป็นเทคนิคที่กระจายโมเดลขนาดใหญ่ไปยังชิปหลายตัว เพื่อมอบประสิทธิภาพที่ดีที่สุดสําหรับโมเดลการเรียนรู้เชิงลึกด้วยพารามิเตอร์มากกว่าหนึ่งแสนล้านตัว อินสแตนซ์ Inf2 ยังเป็นอินสแตนซ์แรกในระบบคลาวด์ที่รองรับการปัดเศษแบบสุ่ม ซึ่งเป็นวิธีการปัดเศษตามความน่าจะเป็นซึ่งให้มีประสิทธิภาพและมีความแม่นยําสูงขึ้น เมื่อเทียบกับโหมดการปัดเศษแบบเดิม อินสแตนซ์ Inf2 รองรับประเภทข้อมูลที่หลากหลาย รวมถึง CFP8 ซึ่งปรับปรุงปริมาณงานและลดพลังงานต่อการอนุมาน และ FP32 ซึ่งช่วยเพิ่มประสิทธิภาพของโมดูลที่ยังไม่ได้ใช้ประโยชน์จากประเภทข้อมูลที่มีความแม่นยําต่ำกว่า ลูกค้าสามารถเริ่มต้นใช้งานอินสแตนซ์ Inf2 ได้โดยใช้ AWS Neuron ซึ่งเป็นชุดเครื่องมือพัฒนาซอฟต์แวร์แบบครบวงจร (SDK) สําหรับการอนุมาน ML AWS Neuron ผสานรวมกับเฟรมเวิร์ก ML ยอดนิยม เช่น PyTorch และ TensorFlow เพื่อช่วยให้ลูกค้าปรับใช้โมเดลที่มีอยู่กับอินสแตนซ์ Inf2 โดยการเปลี่ยนแปลงโค้ดเพียงเล็กน้อยเท่านั้น เนื่องจากการแยกโมเดลขนาดใหญ่โดยใช้ชิปหลายตัวจำเป็นต้องมีการสื่อสารระหว่างชิปที่รวดเร็ว อินสแตนซ์ Inf2 จึงรองรับการเชื่อมต่อระหว่างอินสแตนซ์ความเร็วสูงของ AWS นั่นคือ NeuronLink ซึ่งให้การเชื่อมต่อแบบวงแหวน 192 GB/s อินสแตนซ์ Inf2 ให้ปริมาณการประมวลผลสูงถึง 4 เท่า และเวลาแฝงลดลงถึง 10 เท่าเมื่อเทียบกับอินสแตนซ์ Inf1 รุ่นปัจจุบัน และยังให้ประสิทธิภาพที่ดีขึ้นถึง 45% ต่อวัตต์เมื่อเทียบกับอินสแตนซ์ที่ใช้ GPU อินสแตนซ์ Inf2 พร้อมใช้งานแล้ววันนี้ในแบบพรีวิว หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับอินสแตนซ์ Inf2 สามารถดูได้ที่ aws.amazon.com/ec2/instance-types/inf2
Arup เป็นกลุ่มนักออกแบบ ที่ปรึกษาด้านวิศวกรรมและความยั่งยืน ที่ปรึกษาและผู้เชี่ยวชาญระดับโลกที่ทุ่มเทเพื่อการพัฒนาอย่างยั่งยืนและการใช้จินตนาการ เทคโนโลยี เพื่อสร้างโลกที่ดีขึ้น “เราใช้ AWS ในการจําลองที่มีความซับซ้อนสูงเพื่อช่วยลูกค้าของเราในการสร้างอาคารสูง สนามกีฬา ศูนย์ข้อมูล และโครงสร้างพื้นฐานที่สําคัญในอนาคต พร้อมกับการประเมินและให้ข้อมูลเชิงลึกเกี่ยวกับสภาพอากาศในเมือง ภาวะโลกร้อน และการเปลี่ยนแปลงสภาพภูมิอากาศที่ส่งผลกระทบต่อชีวิตของผู้คนมากมายทั่วโลก” ดร. ซินา ฮัสซันลี วิศวกรอาวุโสของ Arup กล่าวว่า “ลูกค้าของเราต้องการการจําลองที่รวดเร็วและแม่นยํามากขึ้นอย่างต่อเนื่องด้วยต้นทุนที่ต่ำลง เพื่อแจ้งการออกแบบของพวกเขาในช่วงแรกของการพัฒนา และเรามองว่าการเปิดตัวอินสแตนซ์ Amazon EC2 Hpc7g ที่มีประสิทธิภาพสูงขึ้นจะช่วยให้ลูกค้าของเราสร้างนวัตกรรมได้เร็วขึ้นและมีประสิทธิภาพมากขึ้น”
Rescale เป็นบริษัทเทคโนโลยีที่สร้างซอฟต์แวร์และบริการบนระบบคลาวด์ ที่ช่วยให้องค์กรทุกขนาดสามารถส่งมอบความก้าวหน้าทางวิศวกรรมและวิทยาศาสตร์ที่ยกระดับมนุษยชาติ “เวลาแฝงที่ลดลงและประสิทธิภาพเครือข่ายระหว่างโหนดที่ดีขึ้นมีความสําคัญต่อแอปพลิเคชัน HPC ความสามารถในการทําซ้ำและปรับปรุงการออกแบบผลิตภัณฑ์อย่างรวดเร็วโดยใช้ CFD เป็นสิ่งสําคัญสําหรับลูกค้าของเรา ซึ่งให้ความสําคัญกับความยั่งยืนด้านสิ่งแวดล้อมมากขึ้น นอกเหนือจากประสิทธิภาพและความยืดหยุ่นเมื่อใช้งานระบบคลาวด์” มูลยันโต พอร์ต รองประธานฝ่ายคอมพิวเตอร์ประสิทธิภาพสูงที่ Rescale กล่าวว่า “Rescale รู้สึกตื่นเต้นกับอินสแตนซ์ Amazon EC2 Hpc7g ที่มีประสิทธิภาพการประมวลผลจุดลอยตัวมากขึ้น และแบนด์วิดท์ EFA ที่มากขึ้น เรามองว่าการนำประสิทธิภาพด้านราคาที่ดีขึ้นของอินสแตนซ์ Hpc7g มาใช้ร่วมกับประสิทธิภาพด้านพลังงานของโปรเซสเซอร์ AWS Graviton จะพัฒนา CFD และปริมาณงาน HPC ที่ใช้งานจริงไปได้ไกลขึ้น”
AIS มอบทองคำให้ผู้โชคดี 60 รายจากแคมเปญ "AIS Check ID" ชวนลูกค้ายืนยันตัวตนและอัปเดตข้อมูล ลุ้นทองคำต่อเนื่องถึง 30 เม.ย. 68
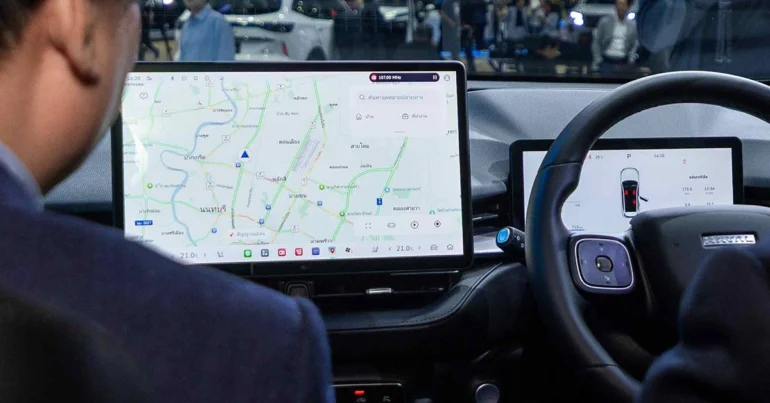
GWM จับมือ HUAWEI เปิดตัวระบบนำทางอัจฉริยะ Petal Maps ครั้งแรกบน ALL NEW HAVAL H6 มอบประสบการณ์ขับขี่ล้ำสมัยด้วยเทคโนโลยี 3D แม่นยำระดับเลน พร้อมข้อมูลเรียลไทม์

OPPO เตรียมเปิดตัว Watch X2 สมาร์ตวอตช์แฟลกชิปใหม่ล่าสุด โดดเด่นด้วยฟีเจอร์ตรวจสุขภาพใน 1 นาที พร้อมยกระดับไลฟ์สไตล์ 8 เมษายนนี้

Neo3 Series สมาร์ทโฟนเกมมิ่งใหม่ล่าสุดจาก nubia พร้อมชิปเซตประสิทธิภาพสูง แบตอึด 6,000mAh และปุ่ม Gaming Triggers เริ่มต้นเพียง 6,999 บาท

Samsung Galaxy A26 5G สมาร์ทโฟนรุ่นใหม่ มาพร้อมระบบ AI ทันสมัย ชิปเซ็ตใหม่เร็วกว่าเดิม 26% ถ่ายวิดีโอ 4K แบตอึด 17 ชั่วโมง ราคา 10,999 บาท

Schneider Charge Pro เครื่องชาร์จรถ EV ระดับมืออาชีพ รองรับทั้งระบบไฟ 1 เฟสและ 3 เฟส มาพร้อมสายยาว 7 เมตรและระบบป้องกันความปลอดภัยขั้นสูง

HUAWEI Mate XT | ULTIMATE DESIGN สมาร์ทโฟนจอพับ 3 ทบ วางจำหน่ายแล้ว พร้อมโปรโมชันพิเศษและของสมนาคุณ มาพร้อมบริการพรีเมียมครบวงจร

AIS ยืนยันความพร้อมระบบแจ้งเตือนภัยฉุกเฉินทั่วประเทศผ่าน Cell Broadcast และ SMS พร้อมใช้งานได้ทันทีเมื่อรัฐบาลสั่งการ

ไมโครซอฟท์จัดงาน SMEs AI Skills Summit มุ่งยกระดับธุรกิจ SMEs ไทย ด้วย AI พร้อมเปิดแพลตฟอร์มเรียนรู้ภาษาไทยฟรี เพื่อเพิ่มศักยภาพในการแข่งขัน
Yango Ads เปิดให้บริการในไทยอย่างเป็นทางการ พร้อมสนับสนุนธุรกิจท่องเที่ยวไทยขยายตลาดสู่ต่างประเทศ หลังพบไทยติดท็อป 3 จุดหมายท่องเที่ยวยอดนิยมในเอเชีย

NEW GWM TANK 300 DIESEL สร้างปรากฏการณ์ยอดจองทะลุเป้ากว่า 800 คันใน 5 วัน มาพร้อมการรับประกันเครื่องยนต์นานถึง 8 ปีหรือ 1 ล้านกิโลเมตร

Zoom ยกระดับการทำงานด้วย AI Companion เทคโนโลยีเอเจนต์อัจฉริยะ พร้อมฟีเจอร์ใหม่มากมายที่ช่วยให้ทีมทำงานได้อย่างมีประสิทธิภาพมากขึ้น